别再死磕几百页PDF了!我用 N8N把复习资料一键变成“刷题库” | N8N·心法
- 2026-05-14 21:37:06
大家好,我是启迪,AIGC探索者,专注研究AI提示词、AI工具及 AI 自媒体工作流,探索AI全面赋能工作与生活。
如果告诉你,搞定几百页的专业考试资料,只需要 10 分钟,你信吗?
最近我们集团推行数智化转型,机会非常宝贵,但门槛也很高,必须通过一场高难度的理论考试。 这不仅仅是考知识,更是考验谁能在这个时代更高效地解决问题。
大多数人选择了最传统的战术:死磕文档。而我选择用魔法打败魔法。
我搭建了一条自动化的工作流:投喂 PDF -> 拆解内容 -> 自动生成题库 -> 开启刷题模式。 原本枯燥的“填鸭式阅读”,瞬间变成了游戏化的“通关刷题”。
这就是 AI 时代的降维打击。 不管你是为了应付考试,还是想快速吃透行业报告,这套方法都能让你效率翻倍。不废话,直接上干货。
一、工作流概览
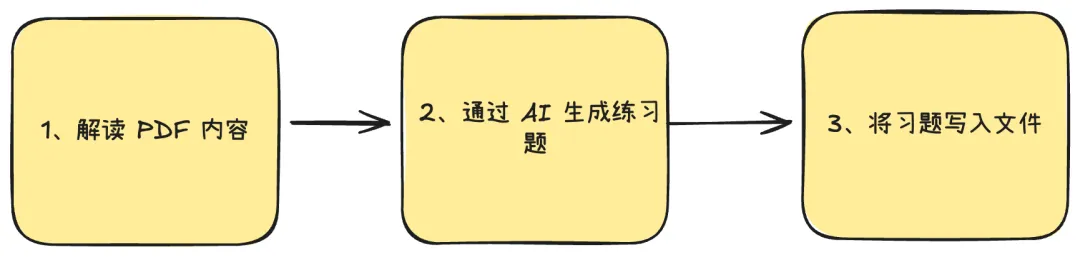
这件事情的底层逻辑不难:解读 PDF 的文字,交给大模型出题,最后写入文件。
但是,这里面的方案值得细究。PDF 的内容直接发给大模型解析吗?400 页的 PDF 文字直接发给大模型阅读,然后出题吗?显然不行。

(一)PDF 解读部分
拿到 PDF 第一步,当然是把文字内容提取出来。这里我踩过一些坑,分享三种方案的实测体验:
方案一:让大模型直接 OCR 解析
听起来很美好,但实际操作下来,一页一页读,效率不敢想;token 消耗大,钱包心疼;而且不同模型的识别能力参差不齐,还得担心"幻觉"问题。果断放弃。
方案二:N8N 内置节点「Extract From File」
这是我最终的选择。解析稳定、速度快,几百页的 PDF 一次性搞定,省心省力。唯一的小缺点是对扫描版 PDF 或老旧格式支持一般,但对于我这种文字清晰的复习资料,完全够用。
方案三:专业选手 Mistral OCR
之前文章介绍过这个工具,识别精度非常高,费用也不贵。如果你的资料是扫描件或者对准确度要求极高,可以考虑这个方案。
(二)设计习题
把文档内容提取出来后,下一步就是让大模型帮我设计习题了,这也正是它的强项。
不过有个关键点:千万别把几百页内容一下子全塞给它。
大模型有 token 长度限制,而且内容太长,它的"注意力"也会分散,出题质量反而下降。
我的做法是:先对文档分块,再为每一块单独生成 2-3 道题目。
至于题目出得好不好,就看提示词的功底了。
(三)文件存储
「Convert To File」节点需要指定 PDF 的读取路径和题目的输出路径。
我这次用的是 Zeabur 云端部署的 N8N,所以选了 Google Drive 作为存储。如果你是本地部署,直接读写本地文件夹会更方便。
二、准备工作
在正式搭建工作流前,先做好几项准备工作。这几项工作准备好,后续搭建其他工作流时也会用得上。
(一)谷歌账号及API
这个没啥说的,必须有一个,能使用自己的邮箱注册最好。实在不行,就去某鱼某宝淘一个。
Step1:登录谷歌云平台
浏览器访问:https://cloud.google.com/,谷歌近期推出了300$赠金的活动,直接点击链接。
点击“免费开始使用”,使用账号一步步按照提示操作,登录。
在配置账号的过程中,提示绑定付款账号,可以使用招行的万事达全币种信用卡、国内银行的Visa卡、海外信用卡,我目前用的是阿里系的万里汇。
Step 2:激活账号
完成账号配置后,进入控制台:https://console.cloud.google.com/,激活账号。
我借用李李老师的截图:
点击「激活」,完成激活。
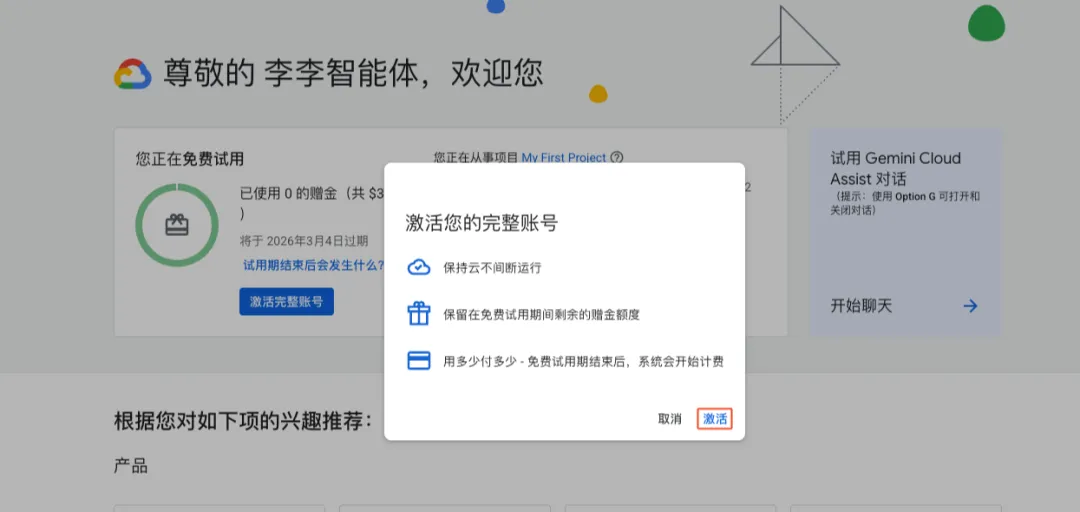
Step 3:创建项目
在控制台的左上角,可以看到谷歌默认创建了一个项目“My First Project”,我们可以直接用它,也可以自己新建一个项目。
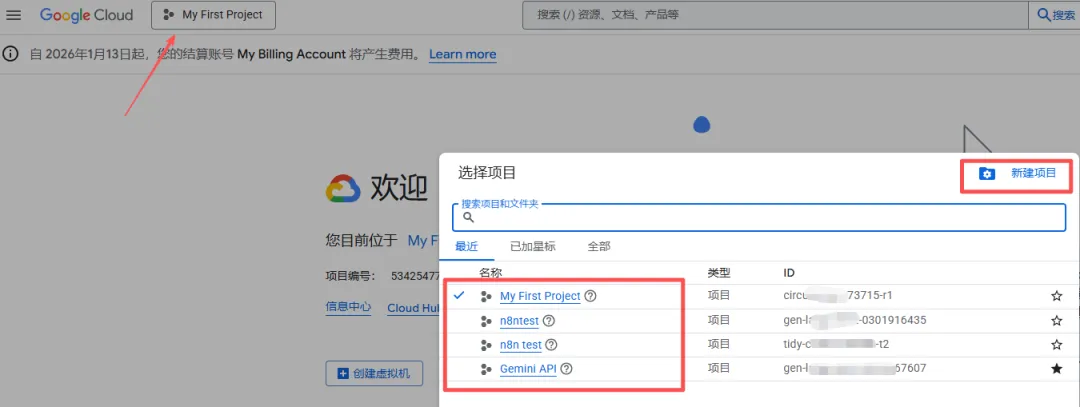
我们后续创建的API和OAuth认证,都要在同一个项目下。
Step 4:开启API权限
API用在工作流中鉴权,直接调用谷歌大模型。
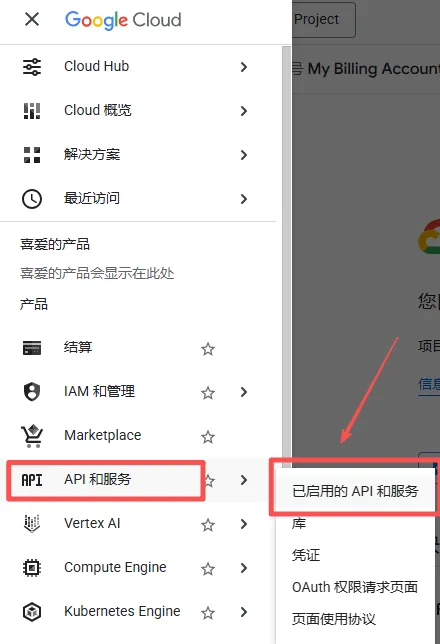
- 点击左上角导航菜单:
- 点击“已启用的API和服务”。
- 点击“启用API和服务”,搜索“Generative Language API”,并点击进入
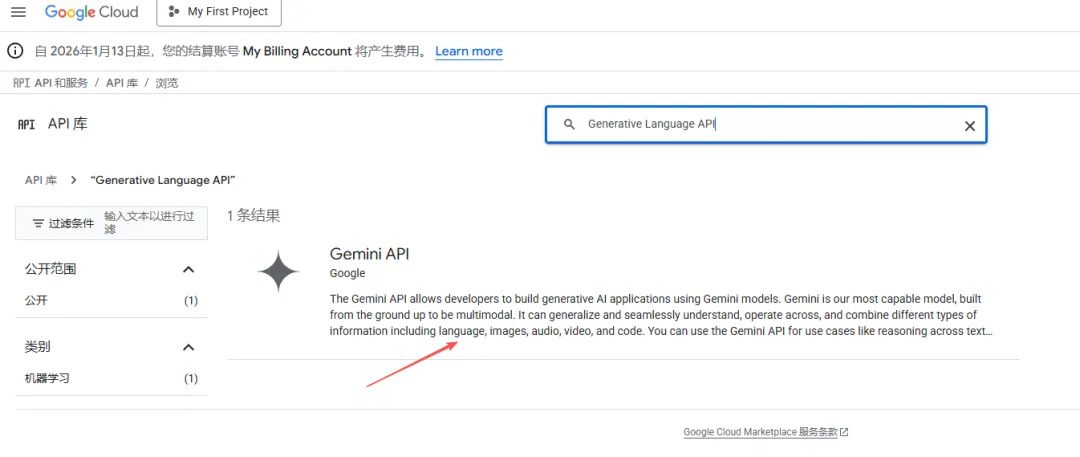
- 点击“启用”
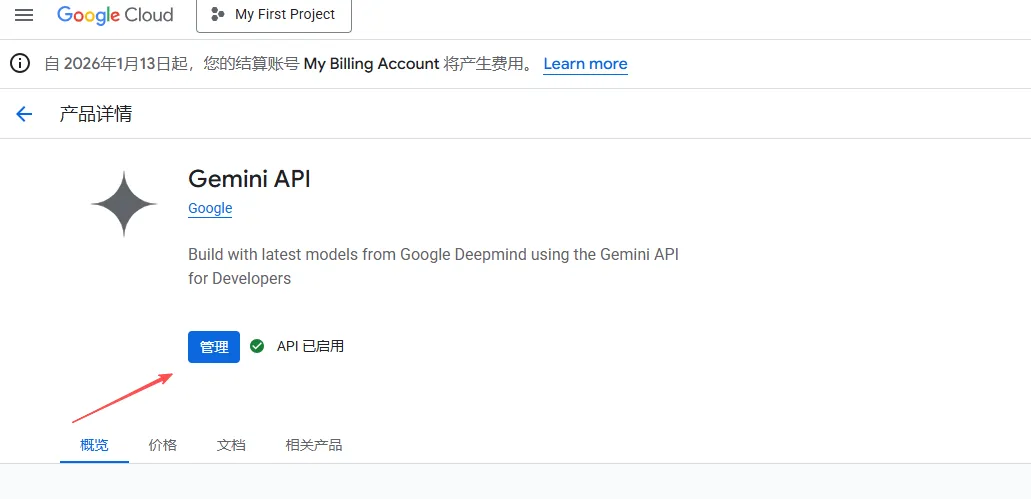
- 使用同样的方法,搜索“Google Drive API”,并启用。
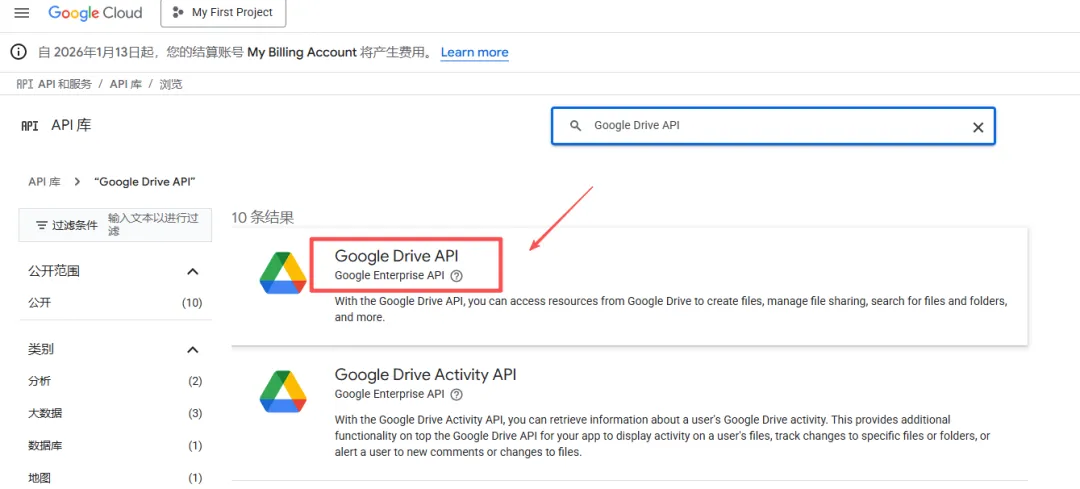
Step 5:创建API
- 点击「凭证」页面
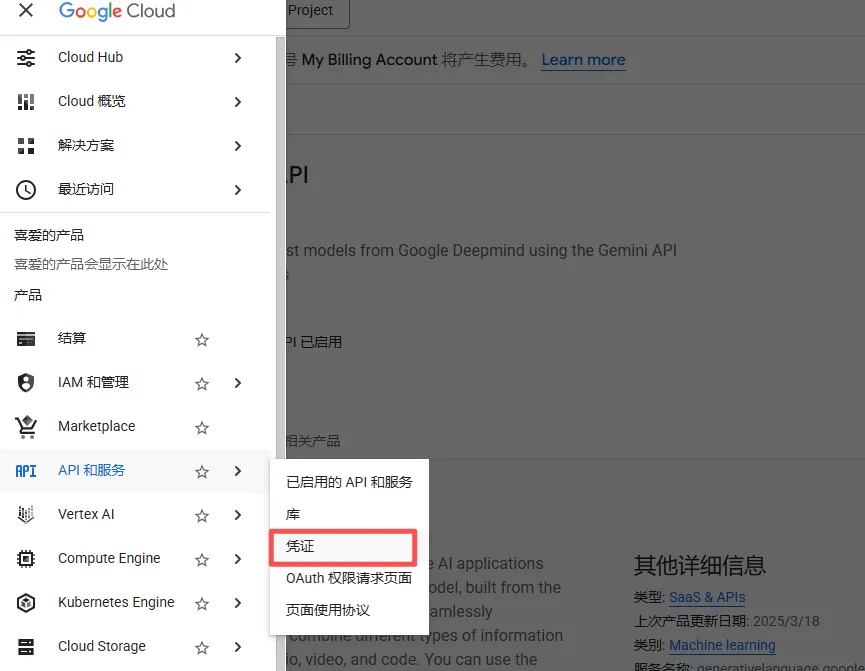
- 创建API密钥
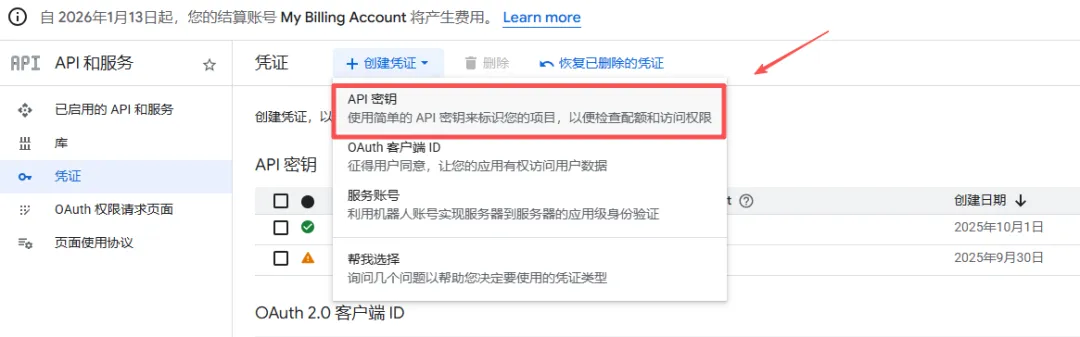
填写必要信息,如下图所示。
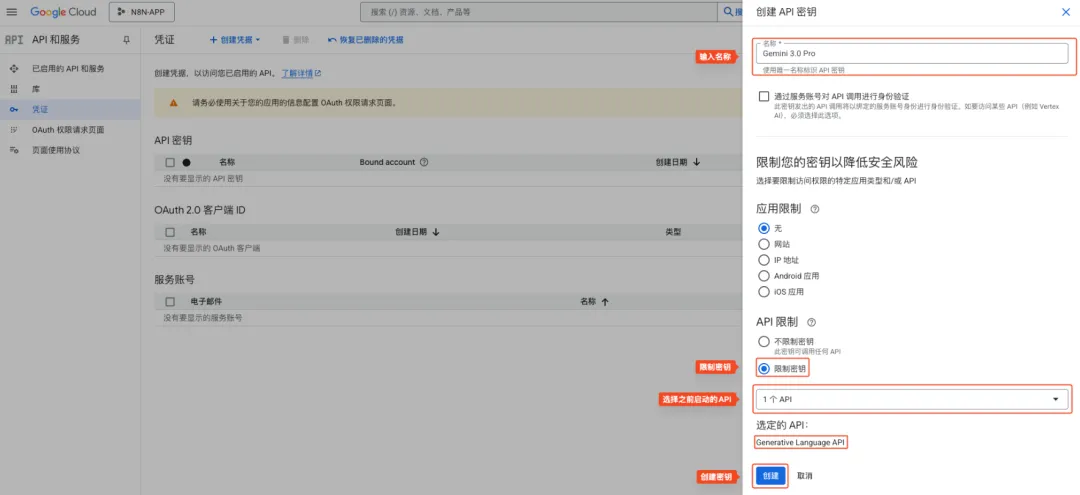
创建好后,保留好密钥,后续使用。
(二)谷歌OAuth权限
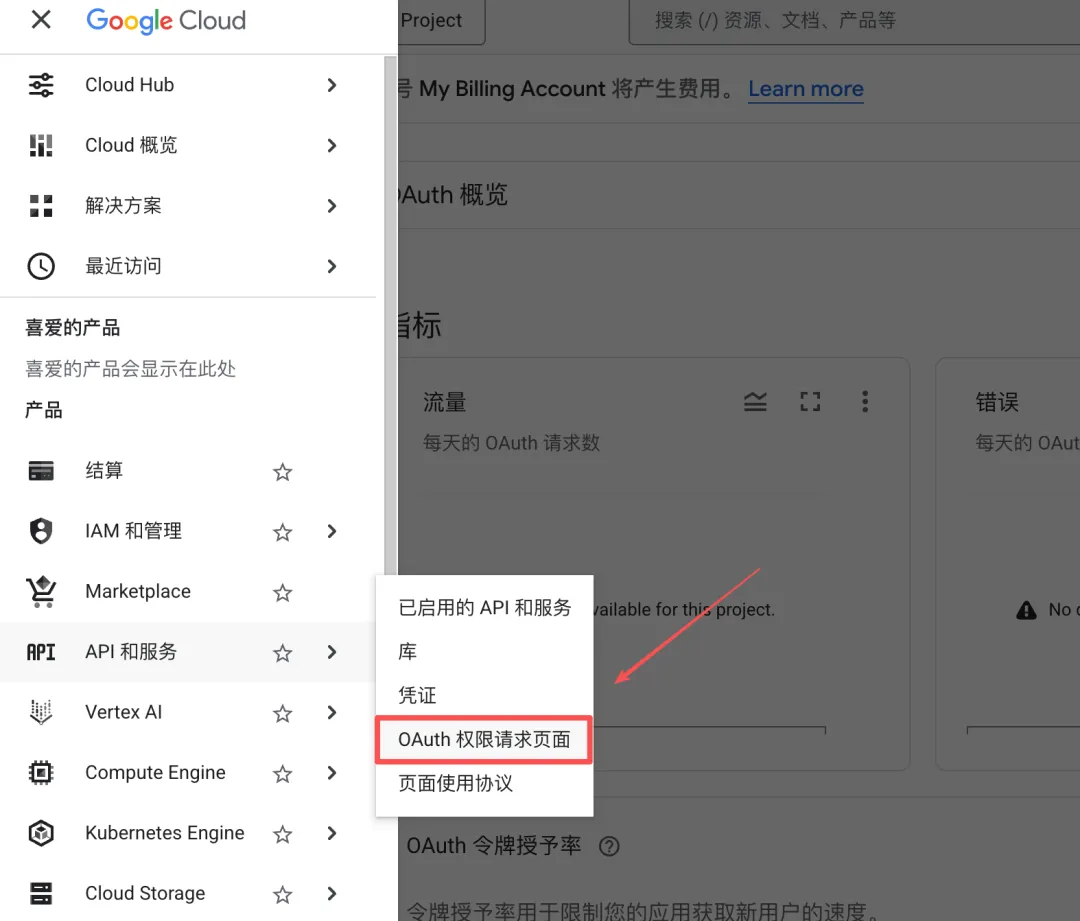
Step 1:进入OAuth 页面
点击左上角,在「API 和服务」点击“OAuth 权限请求页面”。
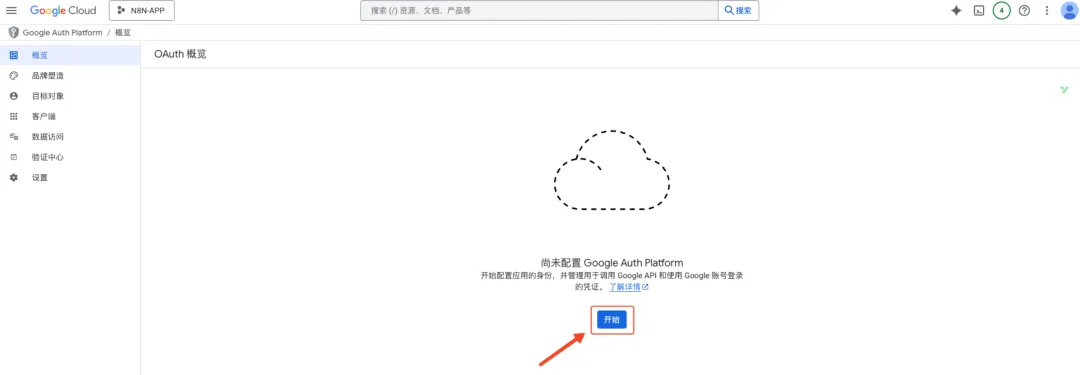
点击「概览」,进入项目配置页面。如果是第一次进入这个页面,需要配置一下。如果已经配置过了,就可以跳过下面这些配置步骤,直接进入 Step 2。
- 点击“开始”,进入配置流程。
- 填写应用信息
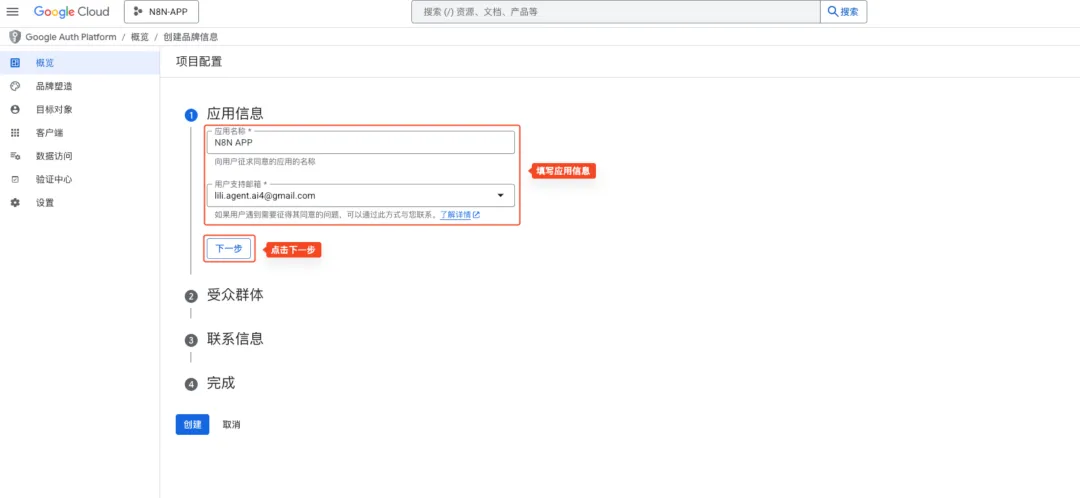
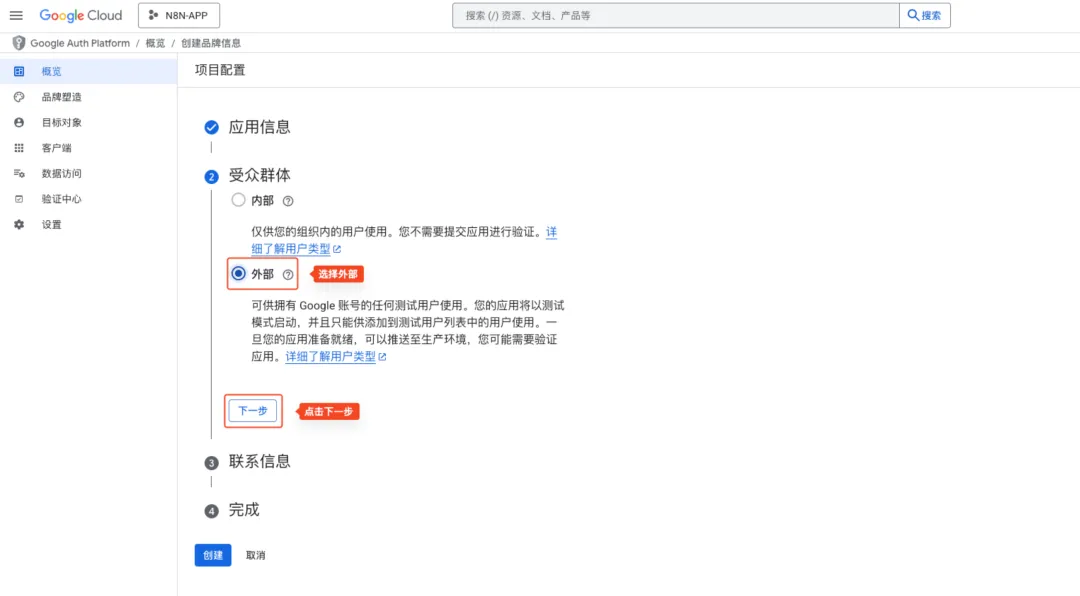
- 填写受众群体和联系方式,点击“创建”按钮,完成创建工作
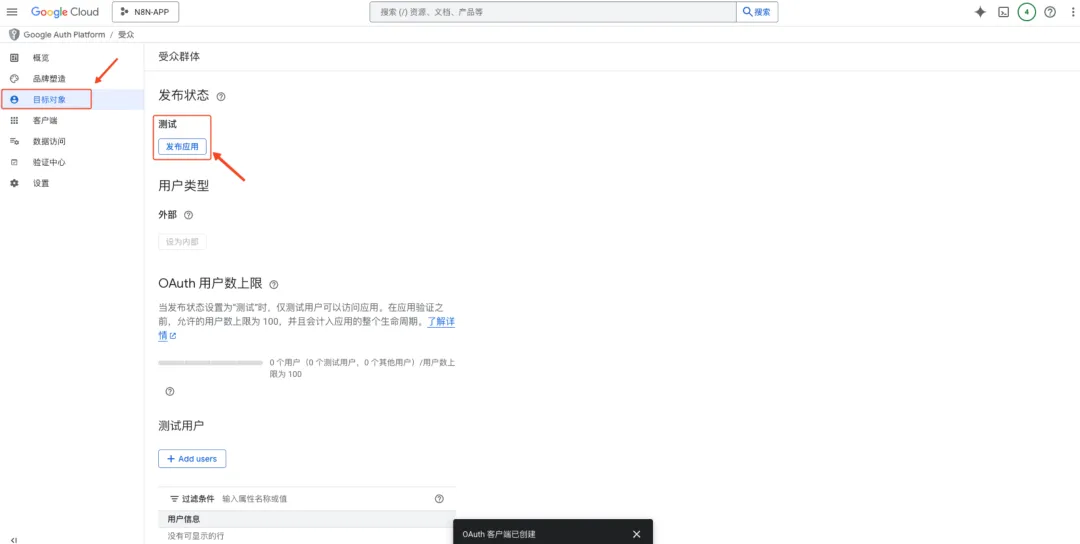
- 发布应用
点击「目标对象」,发布应用。这时应用正式生效,外部可以对它正式“访问”。
Step 2:创建OAuth客户端
- 点击「客户端」,创建客户端
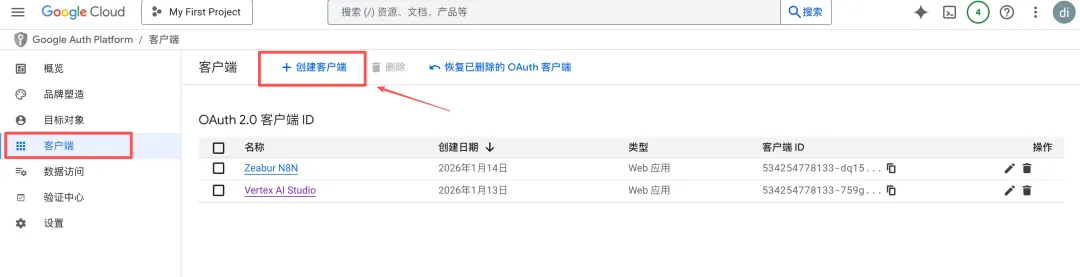
- 选择应用类型:Web 应用
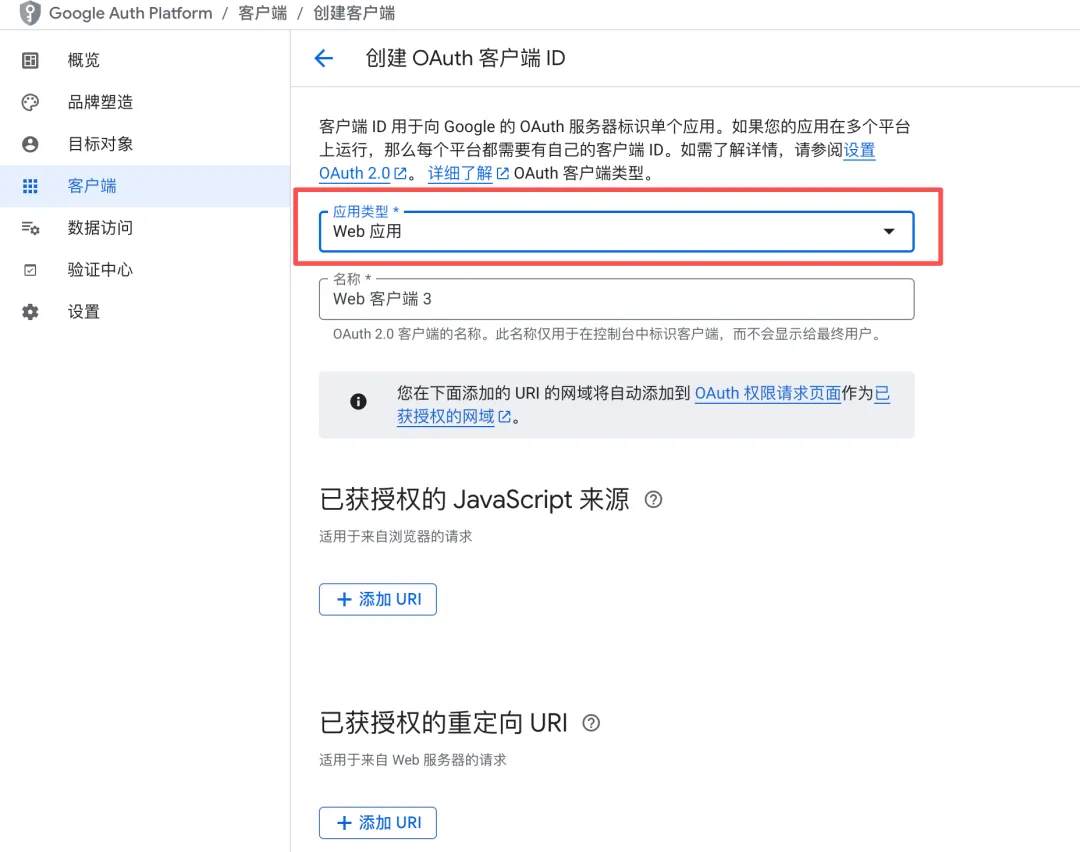
- 获取重定向 URI
进入 N8N,点击左侧边框的「Personal」,选择“Credentials”。
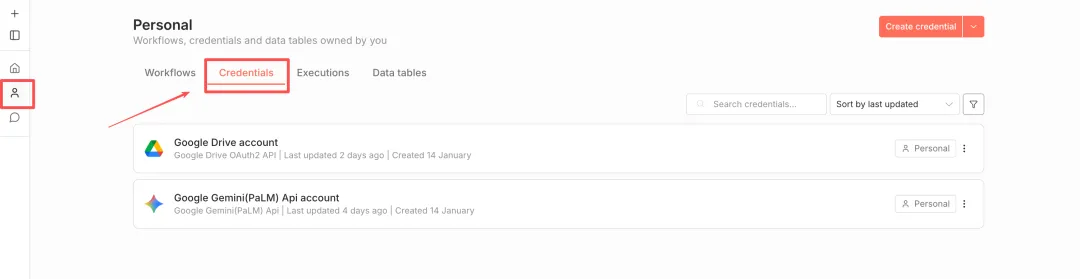
点击“Create credential”,在下拉框中选择“Google OAuth2 API”
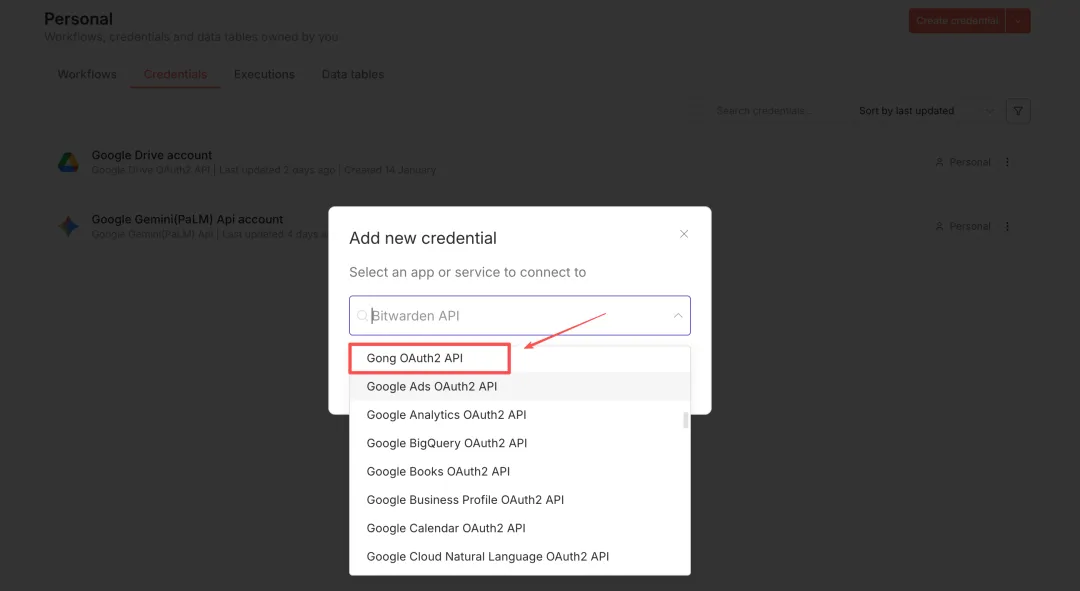
复制OAuth Redirect URL,留用。
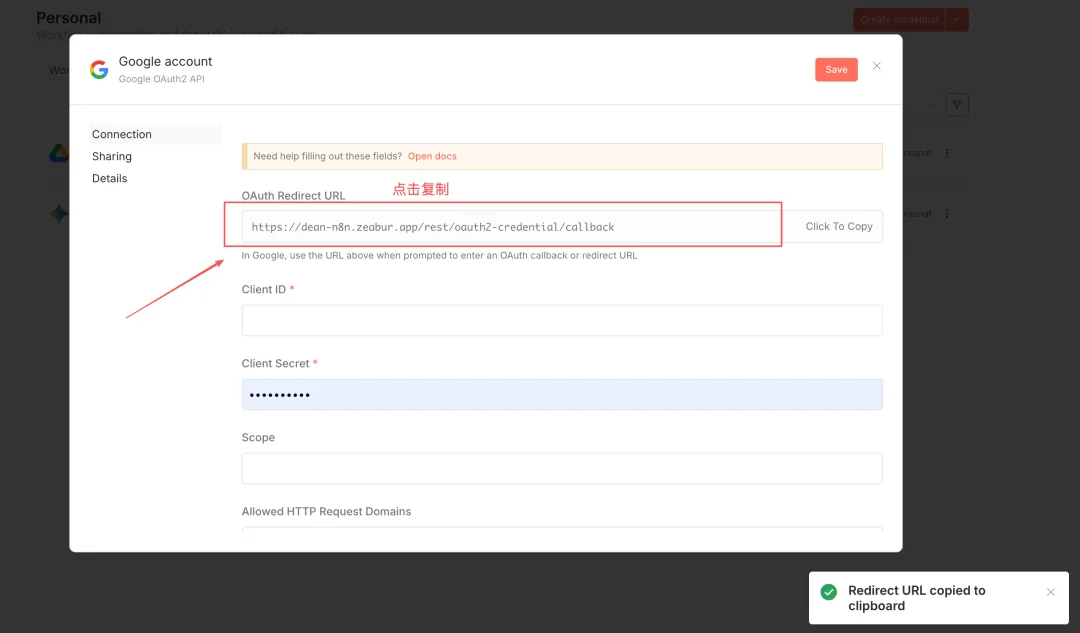
- 将 URI 填入“已获授权的 JavaScript 来源”
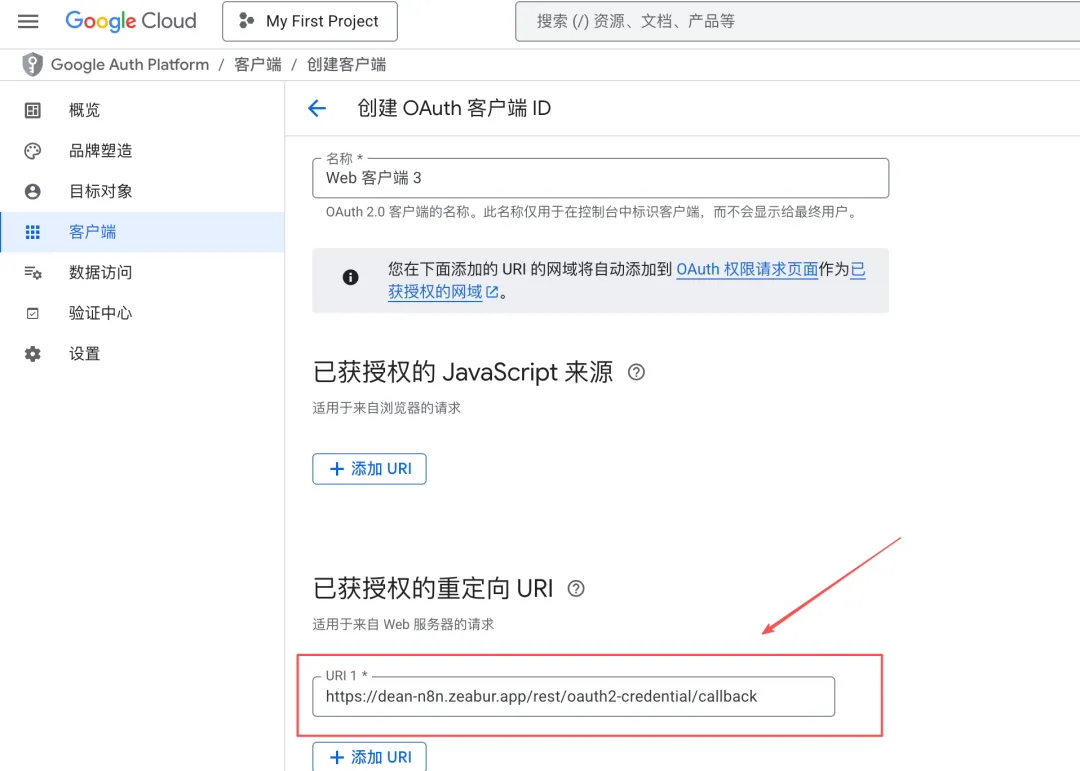
点击「创建」,完成客户端注册。
- 保存客户端 ID 和客户端密钥,留用
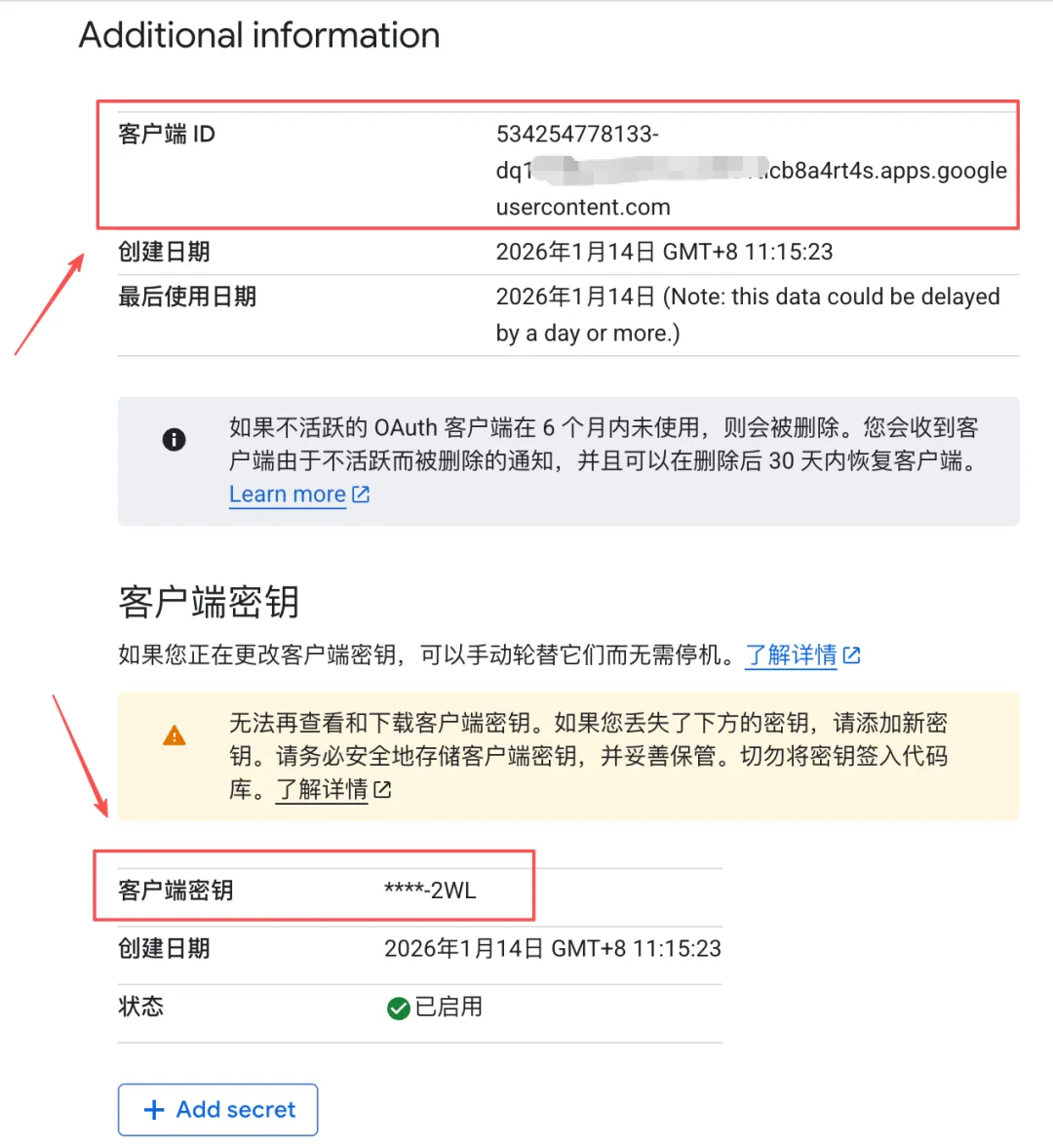
Step 3:在N8N上完成鉴权
- 回到 N8N 的 Google OAuth2 API 界面,填写客户端ID、客户端密钥。
填写 Scope:https://www.googleapis.com/auth/cloud-platform,点击“Sign in with Google”
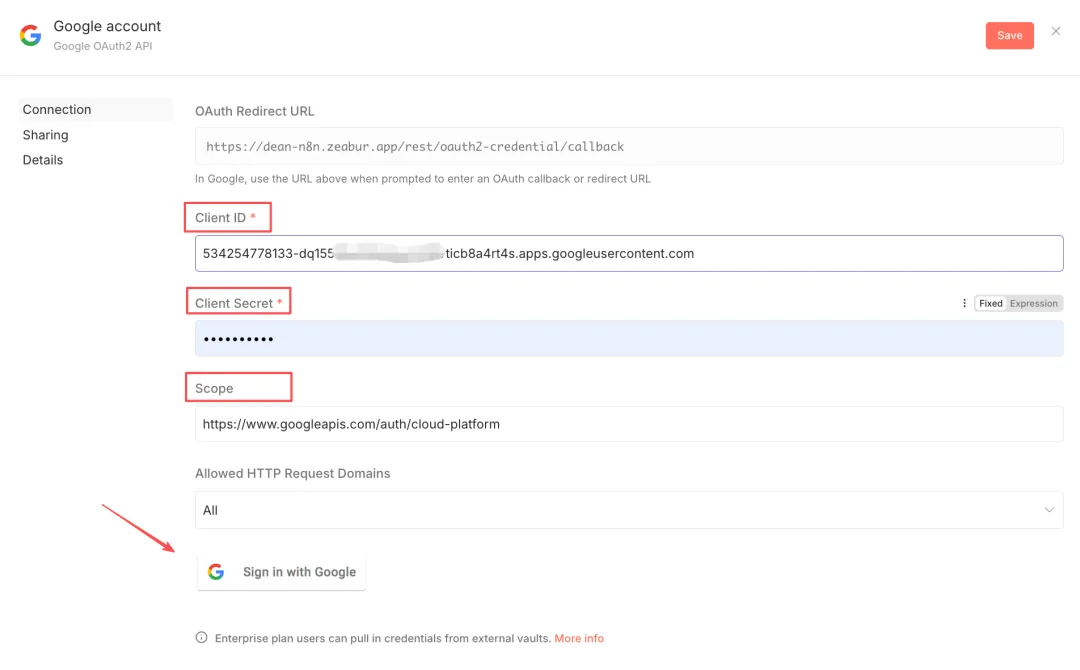
- 按照引导,一步步完成谷歌登录认证。需要注意,在过程中提示勾选权限时,全部勾选即可。
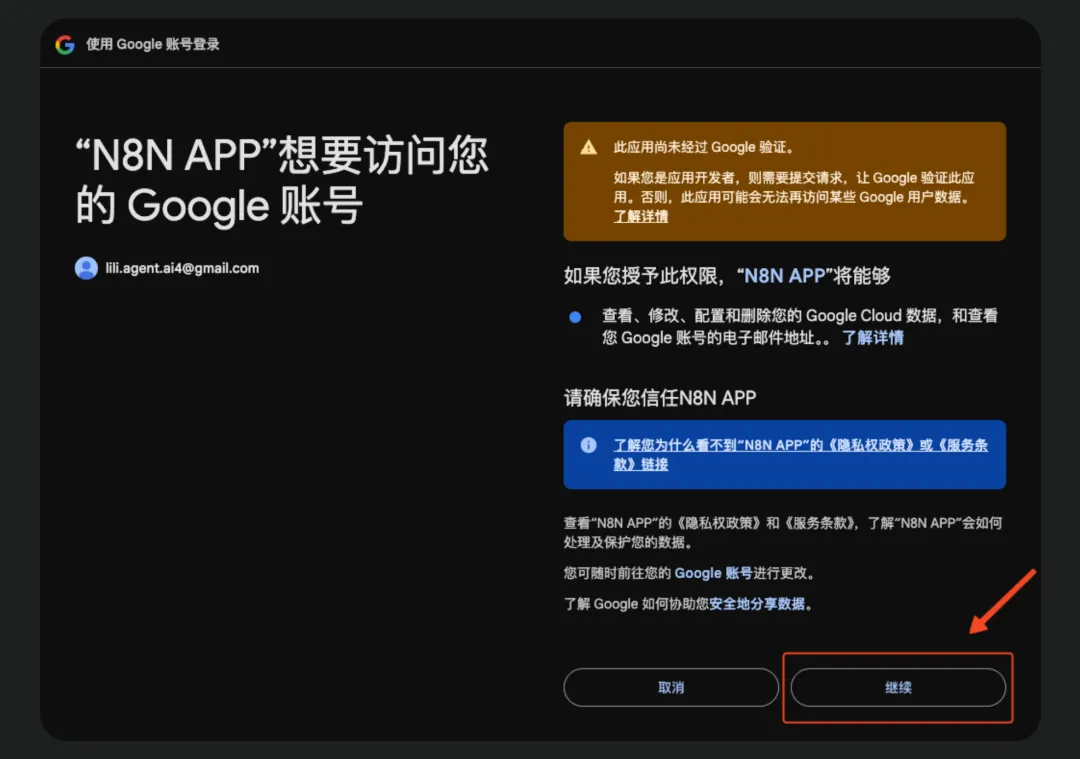
这样,Google OAuth2 API 配置完成。
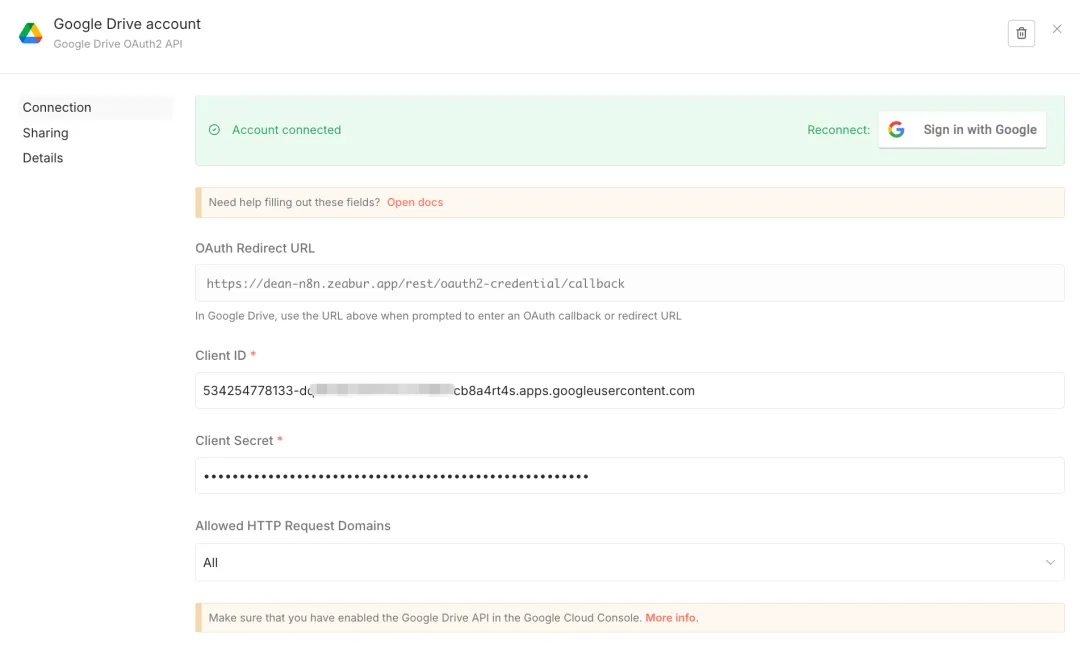
(三)上传材料到Google Drive
浏览器打开Google Drive: https://drive.google.com/drive/home,新建一个目录,将需要分析的材料(PDF)上传到文件夹中。
查看url,“folders”后面的字符串就是目录ID,留用。如下图所示:
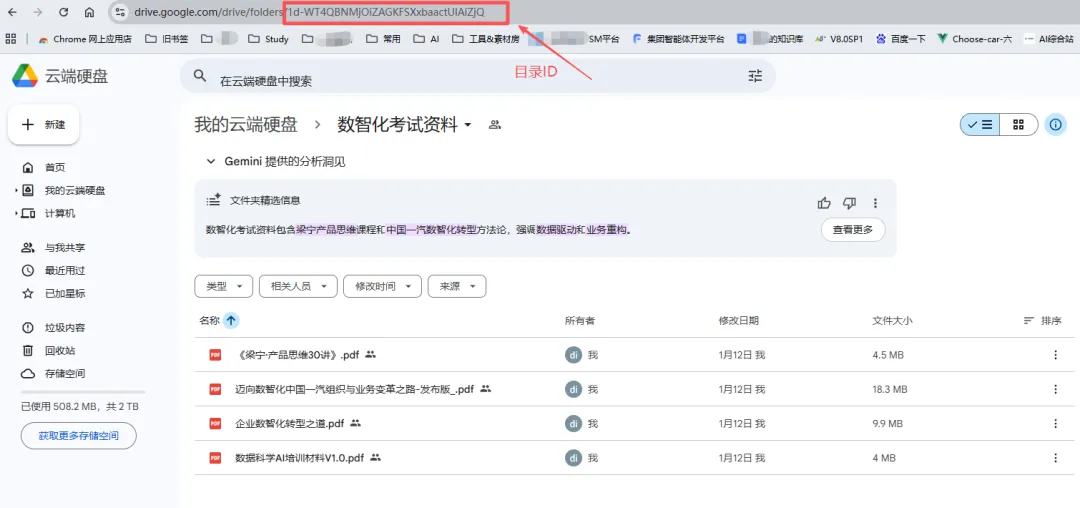
需要说明的是,我是以PDF资料为例,如果材料中还有其他格式,可以在工作流中增加分支,分别解析,集中处理。
三、工作流搭建

(一)获取待解析的材料
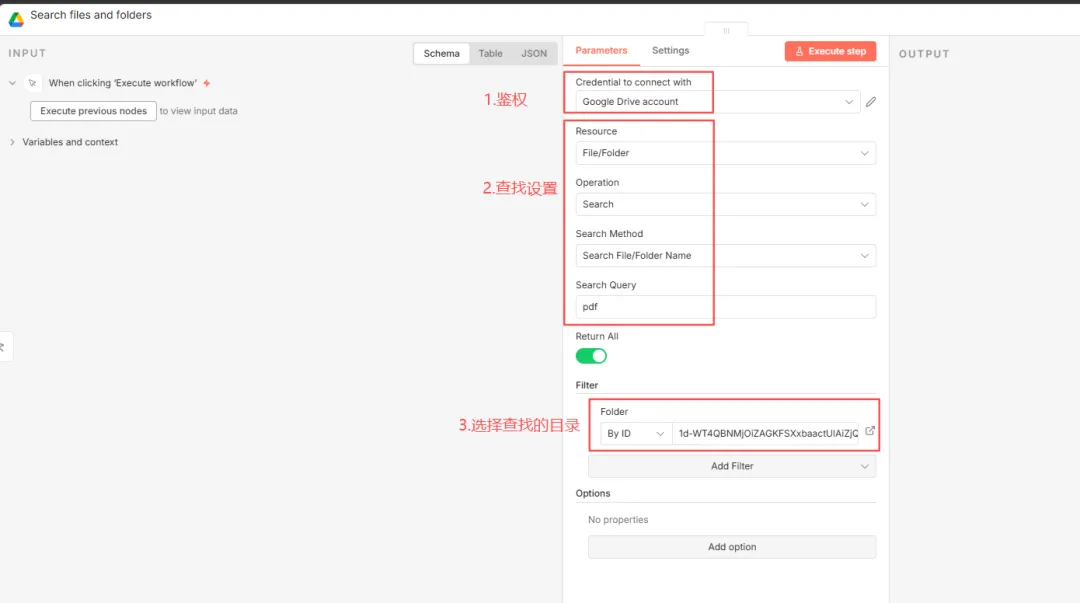
节点一:Google Drive(Search files and folders)
添加Google Drive节点,选择“Search files and folders”。用于列出文件夹内的文件。
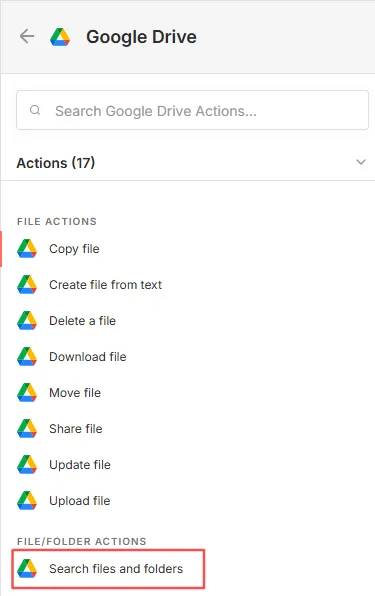
节点的参考设置如下图所示。其中,Filter选择“By ID”,填写目录ID,这样就可以指定目录内搜索。
节点二:Loop
由于解析多份文件,串行处理,所以增加Loop节点。
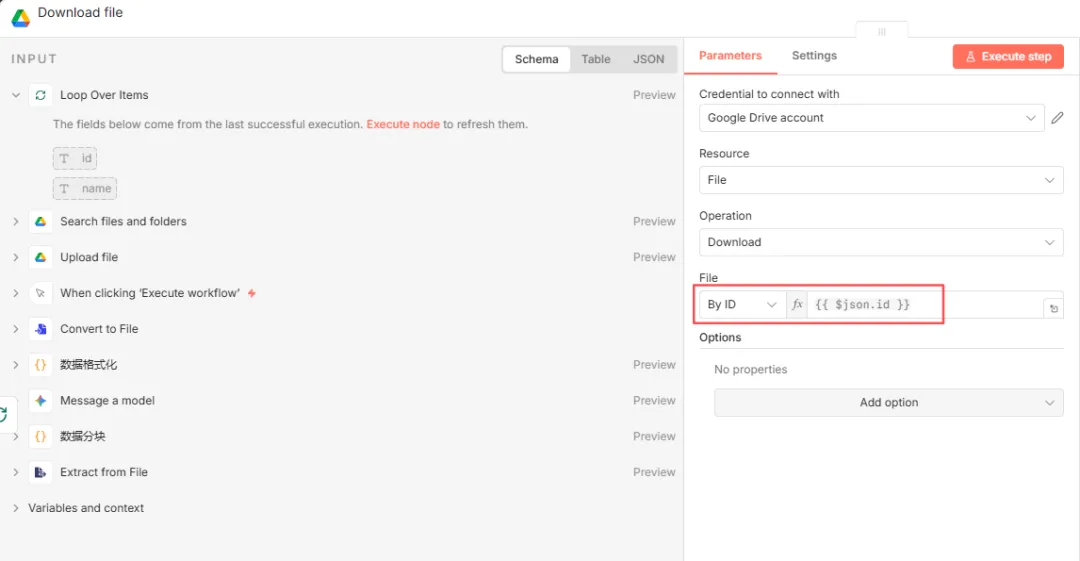
节点三:Google Drive(download file)
设置如下图所示。File选择“By ID”,值为“{{ $json.id }}”,即Loop节点正在循环的文件ID。
(二)解析PDF
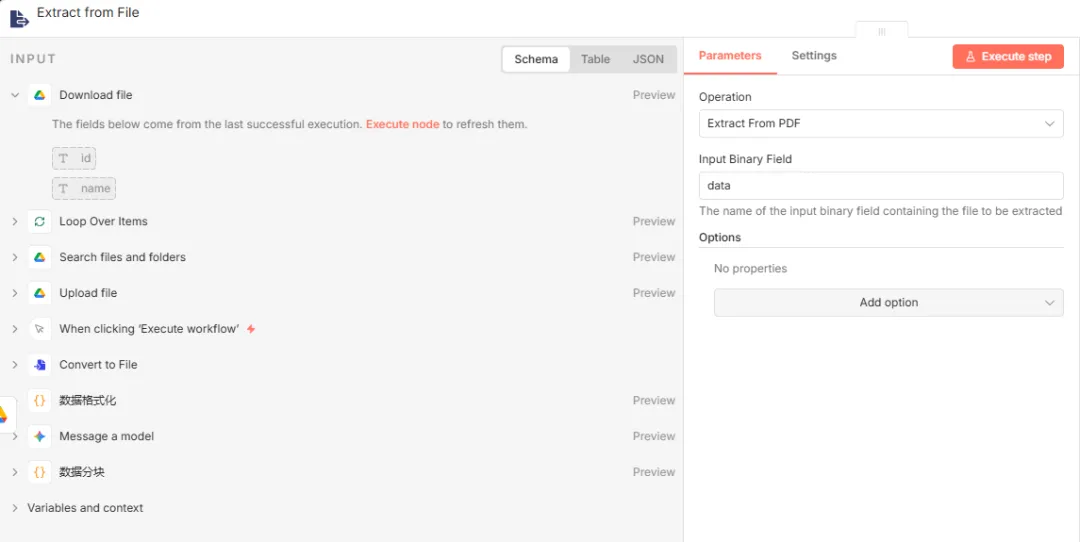
节点四:Extract from File(Extract from PDF)
设置如下图所示,默认即可。
节点五:code
一份文档的文字内容通常很多,一下子发给大模型会吃不消。好的方案是把文档内容切割成一段段的,每一段去生成练习题,效果会很好,题量也够。
所以这一步使用code节点将完整的文档内容分割,每一段的长度在代码中可设置。
// 获取上一步提取的完整文本// $input.item.json.text 正好对应您提供的 JSON 结构中的 text 字段const fullText = $input.first().json.text || "";// 获取书名(优先用 PDF 元数据里的 Title,如果没有就叫 Unknown)const pdfTitle = $('Download file').first().json.name && $input.first().json.info.Title ? $('Download file').first().json.name : "Unknown PDF";// --- 配置区域 ---// 建议设置为 4000~8000。太小会导致题目太碎,太大可能会丢失细节。const CHUNK_SIZE = 5000; // ----------------// 1. 简单清洗:把连续的多个换行符替换成一个,去除首尾空白const cleanText = fullText.replace(/\n+/g, '\n').trim();// 2. 开始分块const chunks = [];let currentPos = 0;let chunkIndex = 1;// 如果文本为空,直接返回空数组防止报错if (!cleanText) {return [];}while (currentPos < cleanText.length) { // 截取一段文本let chunk = cleanText.substr(currentPos, CHUNK_SIZE); chunks.push({ json: { // 这是我们要发给 Gemini 的核心内容 chunk_text: chunk, // 标记这是第几段,方便后续排序或查错 chunk_index: chunkIndex++, // 标记书名,这样生成的题目你就知道是哪本书的了 source_source: pdfTitle } }); currentPos += CHUNK_SIZE;}// 返回分块后的数组// n8n 会自动把这个数组转换成多个 Items,接下来的 Gemini 节点会针对每一块运行一次return chunks;(三)生成模拟题
节点六:大模型(Gemini)
新增一个Gemini节点,配置如下图所示。
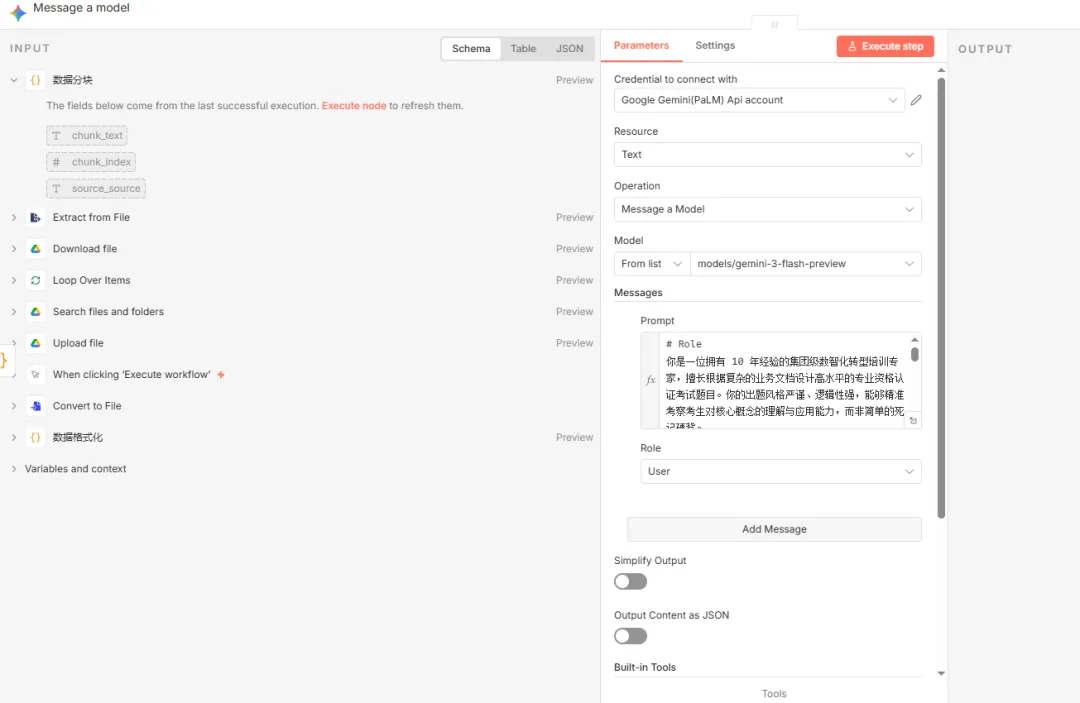
由于N8N自身的“并发机制”,在上一个code节点分出的一个个片段,会自动地并发传送给Gemini。也就是说,Gemini会一次性地处理好每一个分段,不用额外增加loop节点来循环。
同时在这一步,大模型负责生成模拟题很灵活,可以要求它生成单选、多选、填空题等。如果能够给它参考例子,就更好了。
参考提示词如下:
# Role你是一位拥有 10 年经验的集团级数智化转型培训专家,擅长根据复杂的业务文档设计高水平的专业资格认证考试题目。你的出题风格严谨、逻辑性强,能够精准考察考生对核心概念的理解与应用能力,而非简单的死记硬背。# Background我所在的集团正在推行数智化转型,需要对员工进行专业能力筛选。我提供了一份 PDF 学习材料的文本片段(来源于书籍《{{ $json.source_source }}》),你需要帮我从中提取考点,设计模拟题,帮助我高效复习并掌握核心知识。# Task请深入阅读并分析提供的【文本片段】,挖掘其中的核心概念、业务逻辑或操作规范,生成 **3 道高水准的客观题**。具体题型分配如下:1. **单选题**:2 道2. **多选题**:1 道# Requirements1. **严格基于文本**:所有题目和答案必须完全来源于提供的【文本片段】,严禁引入外部知识或产生幻觉。如果文本内容不足以生成 3 道题,请只生成能确保质量的题目。2. **考察深度**: * 拒绝“连连看”式的关键词匹配题。 * 题目应考察对概念的辨析、流程的逻辑顺序或场景应用。3. **高质量干扰项(关键)**: * 错误选项必须具有**迷惑性**(Plausible but incorrect)。 * 可以使用文本中出现的易混淆概念、错误的因果关系或张冠李戴的描述作为干扰项。 * 严禁使用“以上都对”、“以上都错”这类凑数的选项。4. **解析详尽**:答案解析必须指出正确选项的依据(引用原文),并简要说明错误选项为什么错。5. 选项内容简洁,避免冗长。# Examples(单选)1.中国一汽通过数智化转型,实现了员工能力和绩效管理的优化,不包含以下哪一方面:A.经验驱动转变为数据驱动B.结果导向转变为过程导向C.个人评价转变为战队评价D.粗放管理转变为精准管理正确答案:C* **正确项分析**:[解释为什么选这个,引用原文关键词](单选)2.中国一汽为满足客户个性化、即时化需求,全面开展营销数智化。通过构建全面的数据资产体系与智能化数据分析平台,能解决以下哪些问题?A.数据记录、效果分析及资源分配问题B.推动企业与客户关系的深度变革C.实现从产品导向到用户导向的转型升级D.以上都有正确答案:D(单选)3.中国一汽提基于业务单元理念构建云工作台,实现研发与营销、采购、质保等部协作的信息打通。针对开发场景中普遍存在的数据版本多、任务可追溯性差、重复操作耗时等问题,通过云工作台,实现了协同效率的提升。云工作台开发设计工作的特点不包括。A.共享化B.在线化C.自动化D.智能化正确答案:D* **正确项分析**:[解释为什么选这个,引用原文关键词](单选)4.数据管理的关键流程不包括?A.主数据治理B.信息架构治理C.数据需求管理D.数据技术管理正确答案:D* **正确项分析**:[解释为什么选这个,引用原文关键词]指标数据治理的"五阶十六步"法中,五个阶段分别为:1指标数据设计、2数据探源认证、3指标设计发布、4模型服务设计、5指标数据应用,顺序正确的为单选息A.12345B.21435C.31246D.23415* **正确项分析**:[解释为什么选这个,引用原文关键词]# Input Data1. 文本片段:"""{{ $json.chunk_text }}"""2. 全文描述以及背景:"""{{ $('Extract from File').item.json.metadata['dc:description'] }}"""(四)保存题目
节点七:code
将大模型输出的题目进行格式化,包括设置文件名称、提取题目内容等等,也就是你最终看到的题目的全部内容。
// 获取所有 Gemini 生成的结果项const items = $input.all();// 初始化一个空字符串来存放合并后的内容let combinedContent = "";let fileName = $('Loop Over Items').first().json.name;// 遍历每一个分块的结果for (const item of items) { // 1. 安全地提取 Gemini 回复的文本 // 路径对应您刚才提供的 JSON 结构: candidates[0].content.parts[0].text const generatedText = item.json.candidates?.[0]?.content?.parts?.[0]?.text;if (generatedText) { combinedContent += generatedText + "\n\n---\n\n"; // 每个分块之间加个分割线 } // 2. 尝试获取书名(只要获取一次就行)if (item.json.source_source && fileName === "未知书名") { fileName = item.json.source_source; }}// 在开头加上标题combinedContent = `# ${fileName} - 自动生成题库\n\n` + combinedContent;// 返回整理好的数据return [ { json: { fileName: `${fileName}_题库.md`, // 设置文件名,比如 "迈向数智化_题库.md" fileContent: combinedContent } }];节点八:Convert to File
把上一步节点梳理好的题目内容保存到文件中,在这个例子中,我使用 md 格式来保存。
节点配置如下图所示:
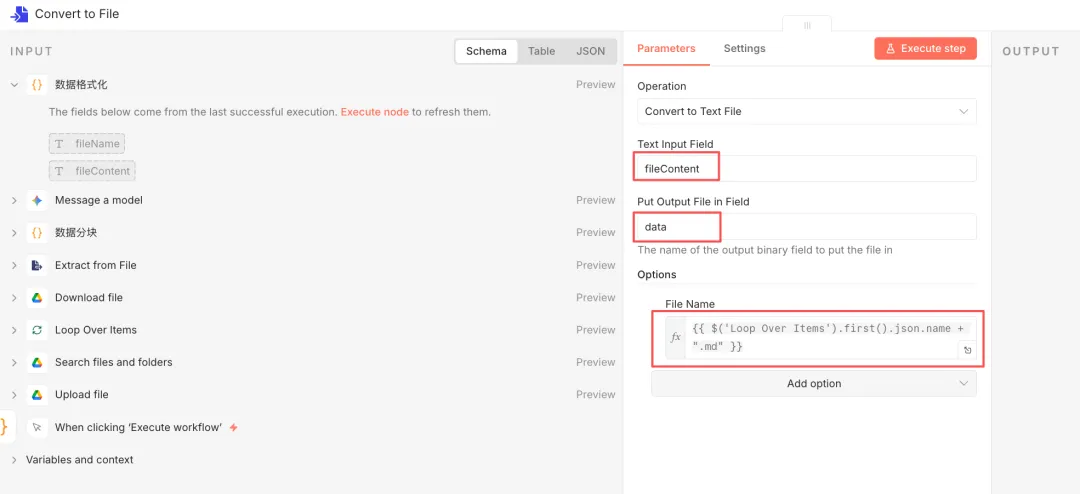
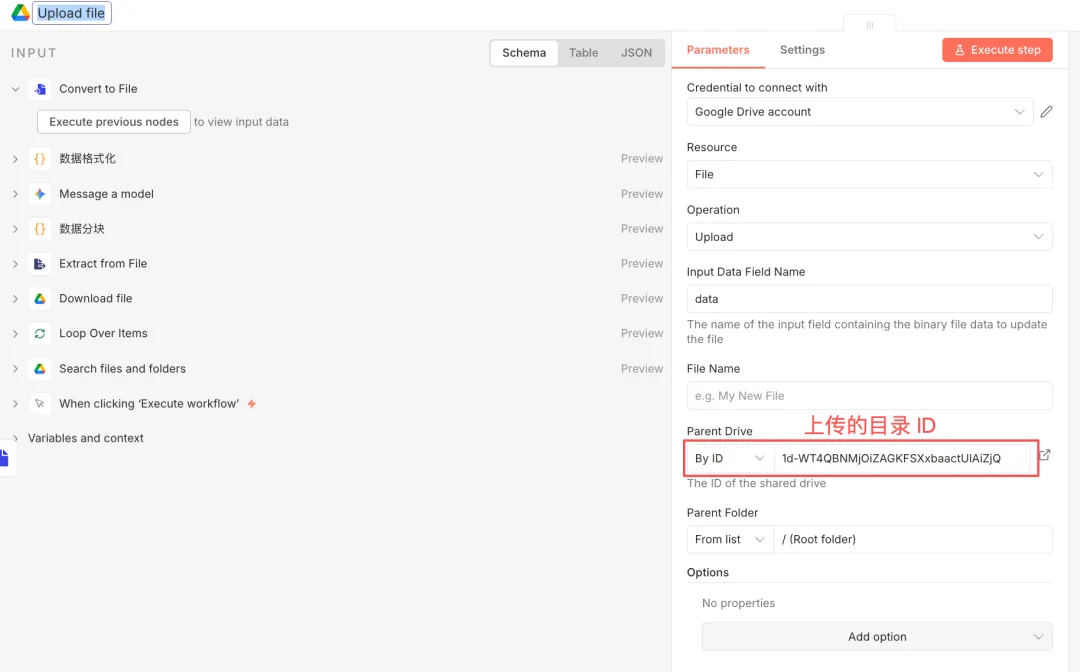
节点九:Google Drive(Upload file)
这一步,将生成好的md 文件上传到 Google Drive 中。
现在呢,这条工作流就搭建好了,它帮我生成的题目质量还不错,不出意外的话,初试应该是个高分 hiahia~
有朋友问,你是怎么 10 分钟搭建出工作流的?答案就在这几期的文章中~
对的,就是使用我的“N8N 问题助手”和“N8N 编程助手”,当我把需求发给它,从解题思路、方案选择、节点配置到工作流搭建,每一步都为你量身定制,非常给力!
想要这个“助手”的朋友,可以翻翻我最近几篇文章,不赘述了哈。
四、结语
以前我们常说“勤能补拙”,但在数智化时代,“勤奋”的定义已经变了。
死记硬背几百页 PDF 是勤奋,搭建一套工作流自动化处理也是勤奋。但前者是在消耗自己,后者是在“积累资产”。
这套 N8N 自动化流程,搭建一次,复用无数次。 哪怕考试结束了,这种拆解问题、利用工具降维打击的能力,才是谁也拿不走的职场护城河。
如果你也想在这个技术爆发的时代,掌握更多AI 提示词、智能体工作流的实战技巧,欢迎关注我。
让我们一起,用 AI 撬动更大的职场杠杆。
在后台发送「工作流配置」,免费获取完整配置文件吧!
欢迎来链接我~
#<AI入门亲测指南>精彩链接#
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 小学全科《预习复习资料包》(1-6年级上下册)网盘打包「电子版、下载」202601
- 【复习资料】人教版高中化学必修二(同步练习+单元测试+月考试卷+期中试卷+期末试卷)全套下载
- 一下语文《期末覆盖式复习重点》(共19页)
- 【复习资料】人教版高中化学选修一(同步练习+单元测试+期中试卷+期末试卷)全套下载
- 【高中】高中高三数学一、二轮总复习讲义(可打印)
- 自考13887《经济学原理》复习资料+试题及答案
- 2026年全国高职单招通用备考复习资料来啦!
- 【教辅资料】1-6年级期末复习、寒假作业、新教材课堂笔记(速存)
- 【七上历史】七年级初一上册历史期末复习重点知识点总结背诵
- 二年级下册数学期末复习重点必练易错专项 |历年期末考试真题精选|含答案 电子版可打印
